
Partitionierende Clusteranalyse
Johannes Lüken / Dr. Heiko Schimmelpfennig
Partitionierende Verfahren zählen neben den hierarchischen zu den bedeutendsten Methoden der Clusteranalyse. Sie gehen von einer gegebenen Klassifikation der Elemente aus und versuchen diese durch Umgruppierungen zu verbessern. Beide Verfahrenstypen sind aber nicht sich ausschließende Alternativen, sondern können gemeinsam eingesetzt werden, um die Stärken beider zu nutzen.
K-Means-Algorithmus
Das bekannteste Verfahren der partitionierenden Clusteranalyse basiert auf dem K-Means-Algorithmus, der folgende Schritte umfasst:
- Für eine vorgegebene Anzahl an Clustern wird eine zufällige Klassifikation ermittelt.
- Für jedes Cluster ist das Clusterzentrum (= Mittelwerte der Variablen über die Objekte eines Clusters) zu bestimmen.
- Jedes Objekt wird dem Cluster zugeordnet, zu dessen Clusterzentrum es am nächsten liegt, das heißt formal die geringste quadrierte euklidische Distanz aufweist.
- Falls es keine Umgruppierung gab, bricht der Algorithmus ab. Ansonsten wird mit Schritt 2 fortgefahren.
Veranschaulichung des Algorithmus anhand des Beispiels aus Abbildung 1:
Abbildung 1a zeigt für ein kleines Datenbeispiel mit vier Objekten, die anhand von zwei Merkmalen beschrieben sind, mit {O1,O3} und {O2,O4} eine mögliche, zufällig bestimmte Ausgangsklassifikation.
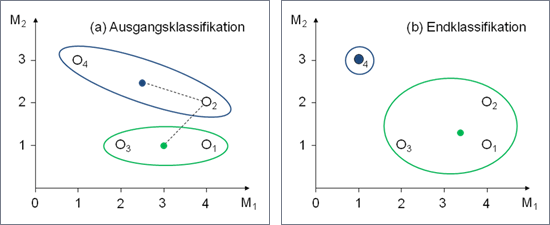
Abbildung 1: Beispiel mit zwei Merkmalen
Nur für Objekt O2 ist die quadrierte euklidische Distanz zum Zentrum · des Clusters, zu dem es nicht gehört, kleiner als zu dem Zentrum · des Clusters, in dem es sich befindet (siehe Abbildung 2). Insofern wird O2 statt dem ‚blauen‘ dem ‚grünen‘ Cluster zugeordnet, so dass sich die Klassifikation {O1,O2,O3} und {O4} ergibt (siehe Abbildung 1b). Da nun kein Objekt eines Clusters mehr zum Zentrum des anderen Clusters eine geringere Distanz aufweist, ist damit auch die abschließende Klassifikation erreicht.
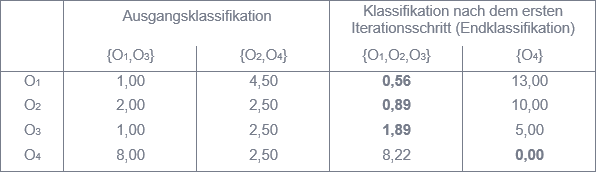
Abbildung 2: Quadrierte euklidische Distanzen der Objekte zu den Clusterzentren

Einfluss der Ausgangsklassifikation
Der K-Means-Algorithmus verfolgt das Ziel, die Streuungsquadratsumme – die quadrierten euklidischen Distanzen der Objekte eines Clusters zum Clusterzentrum summiert über alle Cluster – zu minimieren. Diese beträgt 3,34 (= 0,56 + 0,89 + 1,89 + 0,00) für die Klassifikation {O1,O2,O3} und {O4}. Jedoch ist {O1,O2} und {O3,O4} eine Klassifikation, deren Streuungsquadratsumme mit 3 noch geringer ist (siehe zur Berechnung den Beitrag dieser Reihe in Ausgabe 2/2015). Insofern garantiert der K-Means-Algorithmus nicht, das globale Minimum zu finden. Welche abschließende Klassifikation gefunden wird, ist abhängig von der Ausgangsklassifikation. Schließlich hätte auch {O1,O2} und {O3,O4} bereits die zu Beginn zufällig bestimmte Klassifikation sein können.
In statistischen Softwarepaketen ist die Ausgangsklassifikation zumeist abhängig von der Reihenfolge, in der die Fälle in dem Datensatz vorliegen. Die Ergebnisse eines typischen Datenbeispiels mit 22 auf einer vierstufigen Likert-Skala von 400 Befragten zu beurteilenden Statements mögen die Vielfalt der Ergebnisse illustrieren. Zehn Mal nacheinander wurde jeweils die erste Datenzeile an das Ende verschoben und somit zehn Datensätze leicht unterschiedlicher Reihenfolge erzeugt. Die Anwendung des K-Means-Algorithmus führte zu drei verschiedenen Klassifikationen mit drei Clustern sowie sechs verschiedenen Klassifikationen mit vier Clustern. Nur die Klassifikation mit zwei Clustern zeigte sich als unabhängig von der Reihenfolge der Fälle.
Two-Stage Clustering
Neben der mangelnden Eindeutigkeit des Ergebnisses wird die Notwendigkeit der Vorgabe einer Anzahl an Clustern als Hindernis für die Anwendung von partitionierenden Verfahren angeführt. Diesen begegnet das Two-Stage Clustering. Mit Hilfe eines hierarchischen Verfahrens werden in der ersten Stufe die Anzahl an Clustern und eine Ausgangsklassifikation bestimmt, die in der zweiten Stufe mittels partitionierendem Verfahren verbessert wird. Da das (hierarchische) Ward-Verfahren in jedem Fusionsschritt ebenfalls auf die Minimierung der Streuungsquadratsumme abzielt, bietet sich seine Kombination mit dem K-Means-Algorithmus an.
Beitrag aus planung&analyse 15/3 in der Rubrik „Statistik kompakt“
Autoreninformation
Johannes Lüken war bis 2021 Leiter des Bereichs Multivariate Analysen bei IfaD.
Prof. Dr. Heiko Schimmelpfennig ist Projektleiter für Multivariate Analysen bei IfaD, Institut für angewandte Datenanalyse, sowie Professor für Betriebswirtschaftslehre an der BiTS, Business and Information Technology School, Hamburg. Er ist bei IfaD schwerpunktmäßig für die Beratung, Anwendung und Schulung dieser Verfahren verantwortlich und vertritt in der Lehre das Gebiert der Quantitativen Methoden der Wirtschaftswissenschaft.
Literatur
Bacher, J.; Pöge, A.; Wenzig, K.: Clusteranalyse. 3. Auflage, 2010, München, S. 299-305.
Punj, G.; Stewart; D.W.: Cluster Analysis in Marketing Research: Review and Suggestions for Application. In: Journal of Marketing Research, Jg. 20/1983, Nr. 2, S. 134-148.
<
Share



