
Bestimmung der Clusteranzahl
Johannes Lüken / Dr. Heiko Schimmelpfennig
Im Allgemeinen strebt man an, mithilfe einer Clusteranalyse möglichst wenige Gruppen zu identifizieren, weil eine kleine Anzahl an Segmenten (zum Beispiel Kundengruppen) einfacher zu handhaben ist. Gleichwohl geht eine geringere Anzahl an Clustern immer zu Lasten der Homogenität der Gruppen. Daher werden mit einer Clusteranalyse zumeist mehrere Klassifikationen unterschiedlicher Clusteranzahlen erzeugt, aus denen dann diejenige auszuwählen ist, die beiden Anforderungen am besten gerecht wird. Anhaltspunkte für diese Entscheidung sind neben formalen statistischen Kriterien vor allem Stabilität und Verwendbarkeit der Klassifikation.
Formale Kriterien
Formale Kriterien leiten sich aus dem Ziel der Clusteranalyse ab, in sich homogene und zueinander heterogene Cluster zu finden. Zur Messung der Homogenität einer Klassifikation wird mit der Streuungsquadratsumme (SQS) häufig das Optimierungskriterium von Ward-Verfahren und K-Means-Algorithmus genutzt. Sie erfasst die quadrierten Abweichungen der Objekte eines Clusters zum Clusterzentrum summiert über alle Cluster. Mit geringer werdender Clusteranzahl steigt die SQS monoton an, die Gruppen werden weniger homogen. Trägt man die SQS gegen die Clusteranzahl ab, ist die optimale Anzahl durch einen Knick im Verlauf bestimmt (siehe Abbildung 1). An dieser Stelle nimmt die SQS von einer Clusteranzahl zur nächst kleineren deutlicher zu, das heißt die Heterogenität der Cluster steigt verhältnismäßig stark an. Obwohl es manchmal schwierig ist, diesen Knick zu identifizieren, ist es das am häufigsten genutzte formale Kriterium zur Bestimmung der Clusteranzahl.
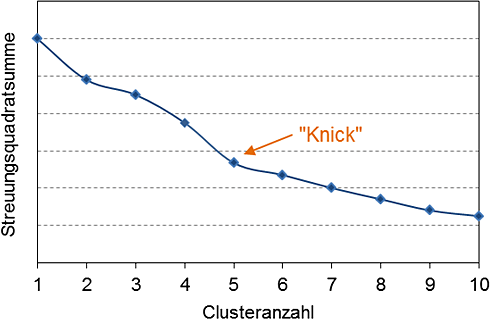
Abbildung 1: Entwicklung der Streuungsquadratsumme
Wie sehr Cluster zueinander heterogen sind, verdeutlichen die (euklidischen) Distanzen zwischen den Clusterzentren. Je weiter entfernt zwei Clusterzentren sind, desto besser sind die Gruppen voneinander getrennt. Wurden alle einfließenden Variablen auf derselben Skala erhoben und die euklidischen Distanzen anhand der Anzahl der Variablen normiert, entspricht die theoretisch maximale Entfernung zweier Cluster der Differenz zwischen größtem und kleinstem Skalenwert. Zur Beurteilung der Trennschärfe können zudem Klassifizierungsverfahren wie die Diskriminanzanalyse oder die Logistische Regression herangezogen werden. Die Variablen der Clusteranalyse sind die Prädiktoren, um die Zugehörigkeit der Objekte zu den Clustern vorherzusagen. Je besser dies für eine Klassifikation gelingt, desto trennschärfer sind die Cluster.
Gleichzeitig Heterogenität und Homogenität einer Klassifikation betrachtet das Variance Ratio Criterion (VRC) von Calinski und Harabasz. Es setzt die Streuung zwischen den Gruppen und innerhalb der Gruppen ins Verhältnis zueinander. Zu wählen ist die Clusteranzahl, für die das VRC maximal ist. In Simulationsstudien mit klar voneinander separierten Clustern hat sich das VRC als das beste aus einer Vielzahl von Kriterien herausgestellt. Bei realen Daten fällt es jedoch häufig monoton mit Erhöhung der Clusteranzahl, so dass immer zwei Cluster die optimale Anzahl wären. Insofern erweist sich das VRC nur als eingeschränkt praktikabel. Stattdessen wird vorgeschlagen, die Clusteranzahl k zu wählen, für die (VRCk+1 – VRCk) – (VRCk – VRCk-1) minimal wird.
Die formalen Kriterien empfehlen nicht immer dieselbe Clusteranzahl. Vielmehr zeigen sie mögliche Klassifikationen auf, die im Hinblick auf Stabilität und Interpretierbarkeit weiter zu untersuchen sind.
Stabilität einer Klassifikation
Die Vergleiche einer Klassifikation mit den Zuordnungen zu den Clustern, die sich ergeben, wenn man die Clusteranzahl sowohl um eins reduziert wie auch erhöht, geben Hinweise auf die Stabilität. Eine Klassifikation ist dann stabil, wenn sich bei der Reduzierung ein Cluster nur aus zwei anderen zusammensetzt, während die anderen im Wesentlichen gleich bleiben, und wenn bei der Erhöhung ein Cluster im Grunde in zwei aufgespalten wird.

Verwendbarkeit einer Klassifikation
Eine Klassifikation muss inhaltlich interpretierbar sein, um sie etwa für Marketingzwecke nutzen zu können. Beispielsweise sollten sich für identifizierte Kundengruppen inhaltlich sinnvolle Bezeichnungen finden lassen. Zur Unterstützung der Interpretation ist die Veranschaulichung der Cluster in Form von Profilen hilfreich. Dargestellt werden die Abweichungen der Mittelwerte der in der Clusteranalyse verwendeten Variablen eines Clusters von den Mittelwerten der Gesamtstichprobe (siehe Abbildung 2).
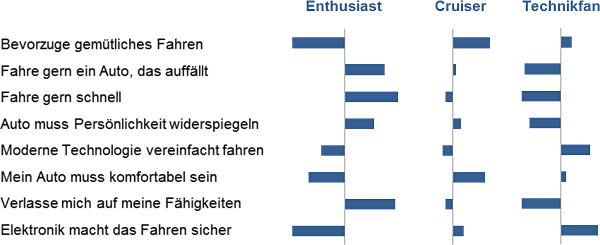
Abbildung 2: Autofahrertypologie
Häufig basiert eine Clusteranalyse auf Variablen, die durch eine Befragung erhoben wurden, weil sie – wie zum Beispiel Einstellungen – nicht direkt beobachtbar sind. Eine Klassifikation ist dann besonders nützlich, wenn sie auch durch unmittelbar beobachtbare, nicht in der Clusteranalyse verwendete Variablen reproduziert werden kann. So kann es das Ziel sein, auf Basis von den in einer Datenbank gespeicherten Eigenschaften der Kunden wie Alter, Geschlecht, etc. die Zugehörigkeit zu einem Kundentyp vorherzusagen. Auch hier kann mithilfe von Klassifizierungsverfahren untersucht werden, wie gut dies für die zur Auswahl stehenden Klassifikationen gelingt.
Beitrag aus planung&analyse 15/4 in der Rubrik „Statistik kompakt“
Autoreninformation
Johannes Lüken war bis 2021 Leiter des Bereichs Multivariate Analysen bei IfaD.
Prof. Dr. Heiko Schimmelpfennig ist Projektleiter im Bereich Data Science bei IfaD sowie seit Oktober 2021 als Professor für Forschungsmethoden an der BSP Business & Law School Hamburg tätig. Zuvor war er sieben Jahre Professor für Betriebswirtschaft und Studiengangsleiter an der University of Applied Sciences Europe. Er ist bei IfaD schwerpunktmäßig für die Beratung, Anwendung und Schulung von Multivariaten Verfahren verantwortlich und vertritt in der Lehre das Gebiet der Quantitativen Methoden der Wirtschaftswissenschaft.
Literatur
Milligan, G.W., Cooper, M.C.: An Examination of Procedures for Determining the Number of Clusters in a Data Set. In: Psychometrika, Jg. 50/1985, Nr. 2, 159-179.
Tuma, M.N., Scholz S., Decker R.: The Application of Cluster Analysis in Marketing Research: A Literature Analysis. In: Business Quest Journal, Jg. 14/2009.
Zenina, N., Borisov, A.: Clustering Algorithm for Travel Distance Analysis. In: Information Technology and Management Science, Jg. 16/2013, Nr. 1, 85-88.
<
Share



